


Afternoon project: JPEG DCT text lossifizer
Answering questions that ought not to be asked.
Earlier this month, I posted a gentle introduction to two pivotal frequency-domain algorithms: discrete Fourier transform (DFT) and discrete cosine transform (DCT). The first one has countless applications in signal processing, from Auto-Tune to MRI. The second one reigns supreme in the world of lossy compression — including JPEG, MP3, and H.264. I penned that deep dive simply because I could never find an intuitive and satisfying explanation of how and why these algorithms work.
In the course of writing the article, I crafted two compact implementations of the algorithms, so I had an itch to put them to some use. After some deliberation, I decided to answer the age-old question: what would happen if you applied lossy frequency-domain compression to text?
I followed the JPEG approach: I employed DCT to turn “time”-domain data (left-to-right text) into a series of frequency coefficients. I then quantized (reduced the precision of) the coefficients. Finally, I performed inverse DCT to go back to reduced-fidelity text.
Well, without further ado — I present you the Text Lossifizer:

Yep. It’s now a thing.
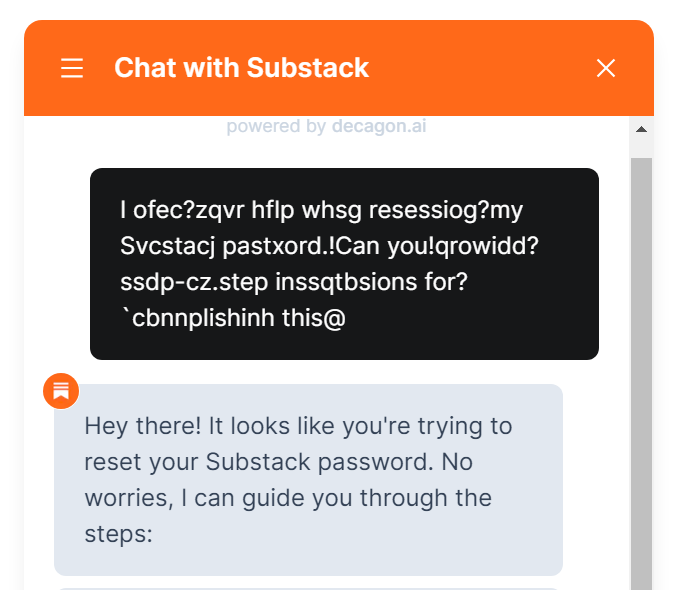
My initial version used ASCII codes as a way to map text to the numerical representation needed for the transform. This meant that as the coefficients lost precision, letters were likely to be substituted by their ASCII table neighbors. The approach preserved the overall structure of the text, but quickly made the individual words hard to parse:

Well, hard to parse for humans, anyway — LLMs are fairly undeterred by lossy compression; here’s Google Gemini deciphering the ruined text with ease:
")
Sometimes, you end up tripping the LLM’s “gibberish detection” pre-filter that scolds you with a canned response. But when the approach works, it’s a marvelous way to communicate with machines:
In any case: some time after I shared the initial prototype, Matt Weeks (scriptjunkie) observed on Twitter that the algorithm performs much better if you convert text to numbers using indices into a "perceptual” character table instead of ASCII. The hand-crafted table is just a reordering that places similar-looking or similar-sounding characters next to each other; for example, we made a cluster of uppercase and lowercase “I”, uppercase and lowercase “L”, the digit “1”, and punctuation characters “|” and “!”.
The results are pretty spectacular; the text remains legible even at very high quantization settings. For example, with the slider most of the way to the right, the original ASCII algorithm transformed "hello cruel world" into the intelligible “igpop"fpscg?vptk`”. Meanwhile, the perceptual algorithm yields the semi-legible drunken l33tspeak of "jELL0~kruAL mOmlt".
In the JPEG file format, the quantization algorithm reduces the accuracy of higher-frequency components more aggressively. This is because human vision is not particularly sensitive to the exact luminosity of every grain of sand or every strand of hair. In the text domain, I found that the opposite is true: higher-frequency components, which define the relative delta from one character to another, matter more than low-frequency shifts. The text lossifizer implements this inverted weighting.
What’s the point of it? None, really, other than satisfying some geeky curiosity. But it’s a pretty mesmerizing toy to play with for five minutes or so, and it’s a good way to demystify an important and useful algorithm. The whole web app is a single file with fewer than 150 lines of code, so feel free to view source (Ctrl+U) to learn more.
👉 For a thematic catalog of posts on this blog, click here.
To preempt the pedantry: the way JPEG works is that it performs this lossy transformation, and then compresses and decompresses the quantized coefficients using traditional lossless compression (Huffman coding). There's also a color space transform and chroma subsampling beforehand, but that's not relevant to text.
Anyway, this page is skipping the lossless compression and decompression parts because they would have no effect on the data. The entire point is to demonstrate the degradation you'd experience if you applied the same algorithm to text, similar to simulating the impact of JPEG compression from the original input bitmap to your screen.
It's a great password generator as well