
Approximation game
The number 22/7 and the pigeon flocks of Peter Gustav Lejeune Dirichlet
In some of the earlier articles on this blog, we talked about the nature of real numbers and the meanings of infinity. The theory outlined in these posts is interesting but also hopelessly abstract. It’s as if we’re inventing make-believe worlds that have no discernible connection to reality.
In today’s post, we’ll examine a cool counterexample: an outcome of an numerical experiment that can be backed up with fairly simple proofs, but that makes sense only if you take a step back to consider the construction of real numbers and rationals.
We start by picking a real number r. Your job is to approximate it as closely as possible using a rational fraction a / b with a reasonably small denominator. The approximation can’t be the same as r. Is this task easier if r itself is rational or irrational?
Make a guess and let’s dive in. For simplicity, we’ll stick to a positive r and positive fraction denominators throughout the article.
Defining “good”
For a chosen denominator b, it’s pretty easy to find the value of a that gets us the closest to the target r. We must consider two cases: the largest “low-side” fraction that’s still less than r; and the smallest “high-side” fraction greater than r. If there’s a rational fraction that matches r exactly, that solution is prohibited by the rules of the game; we need to pick one of the nearby values instead.
If you wanted to find an exact match, you could try aideal = r · b; this makes the a / b fraction equal to r · b / b = r. That said, r · b might not be an integer (or even a rational number), so even without the added “no exact matches” rule, the approach is usually a bust.
If we round the value up (⌈r · b⌉), we get a number that is equal or greater than aideal; if it’s greater, the difference between the two values will be less than 1. In other words, we can write the following inequality:
This is saying that the rounded-up number may be equal to the ideal solution needed to match r exactly, or it might overshoot the target, but always by less than the minimum possible increment of the numerator in the a / b fraction.
The result is almost what we need, but once more, the rules prohibit approximations that are exactly equal to r. The workaround is to subtract 1 from all sides of the inequality:
The effectively tells us that the middle term — ⌈r · b⌉ - 1 — is always less than the value needed to match r, but the difference is never greater than a single tick of the numerator. We’re as close as we can be; the value of a for the optimal low-side approximation (a / b < r) is:
We can follow the same thought process to find the high-side estimate (a / b > r); this time, we round the product down and then add 1:
Finally, the error (ε) associated with any a / b can be easily calculated as:
Earlier in the process, we have established that if we pick alow or ahigh, the error can’t exceed one tick of the numerator, which works out to a difference of ± 1/b. As a practical example, if we’re trying to approximate r = 2 using b = 5, the best inexact solutions are 9/5 = 1.8 on the low side and 11/5 = 2.2 on the high side; they both have an error of 1/b = 0.2.
Next, we’ll try to examine if the error can be less. If we find any approximations that are better than the worst-case scenario — i.e., that satisfy ε < 1/b — we’re gonna call them 1-good.
As an inspection aid, we can also define a denominator-normalized approximation score s, calculated by multiplying ε by b:
This keeps the maximum error at 1 regardless of the denominator we’ve chosen. By that metric, a 1-good approximation is associated with s < 1.
The rational test case
Now that we have the mechanics spelled out, let’s take r = 1/4 and analyze the optimal solutions for some initial values of b:
We find that many approximations are 1-good (ε < 1/b, s < 1) and that some seemingly outperform their immediate peers; for example, 1/5 = 0.2 is better than 2/6 ≈ 0.333. Nevertheless, the results are underwhelming: the values diverge from the 1/b baseline by small factors that are stuck on repeat. If we plot a larger sample, we get:
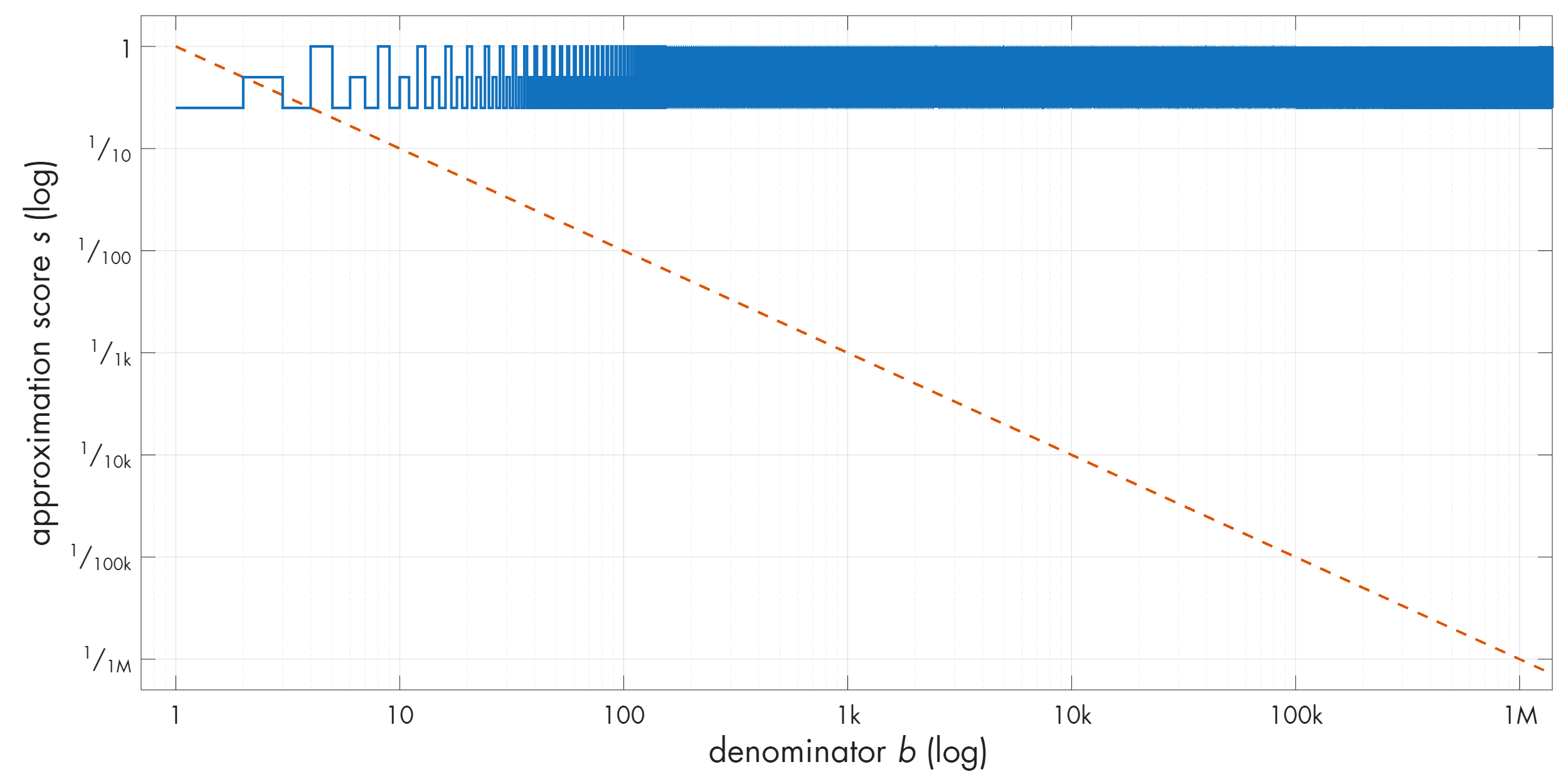
In this log-scale plot, I also included a diagonal line that represents error values decreasing with the square of the denominator (1/b²). Approximations for which the error dips below this line would be markedly better than the ones that merely dip below 1/b. We can label these 1/b² solutions as 2-good.
In the plot, we see two trivial approximations below the 2-good line, but for a rational r, we can prove that the effect can’t last. We start by rewriting r as a fraction of two integers: r = p / q, which is (by definition) possible for any rational. The 2-goodness criteria is ε < 1/b². We’ve previously defined the approximation error ε as | r - a/b |, which we can also restate as | p/q - a/b |. Per the rules of the game, valid solutions must have an error greater than zero. Putting it all together, we can write the following inequality that spells out the requirements for 2-good approximations of rationals:
To tidy up, we can bring the middle part to a common denominator:
The denominator b · q is positive, so there’s no harm in taking it out of the absolute-value section and multiplying all sides of the inequality by it:
All the variables here are integers. If we consider the b ≥ q case, the fraction on the right is necessarily ≤ 1. That creates an issue because it implies the following:
Again, the middle section comprises of integers, so it can’t possibly net fractions. In effect, the equality says: 0 < integer < 1; there’s no integer that satisfies this criterion, so the assumption of b ≥ q leads to a contradiction. If any inexact 2-good approximations of rational numbers exist, they can only exist for b < q.
That’s where we look next. If the target real r = p / q is given at the start, then q doesn’t change and the b < q condition restricts the solutions to integer a / b fractions with denominators smaller than q. There’s only a finite number of these.
To address one natural objection, we don’t get more latitude for b by rewriting r to use proportionately greater q and p — for example, by restating r = 1/2 as r = 4/8. If we multiply both the numerator and the denominator by the same factor — say, 4 — we go from the original inequality:
…to:
…which is the same as:
This amounts to multiplying all sides of the earlier inequality by a constant factor; the right-hand ceiling is proportionately higher, but so is the stepover of the middle expression, netting us exactly as many solutions as before. In effect, if any 2-good approximations of a rational number r exist, there can’t be more of them than allowed by the b < q criteria for the lowest-terms representation of r = p / q. And these solutions, if any, will be clustered on the left side of the plot because they must obey b < q.
This is about as much as we can squeeze out of that stone. The bottom line is that rational numbers are difficult to approximate using other rationals; in fact, the simpler the number, the fewer good approximations we get.
Approximating irrationals
If rationals tend to be relatively resistant to approximations, it might be tempting to assume that the situation with irrational numbers is going to be worse. But, to cut to the chase, here’s the plot of approximations for r = π:
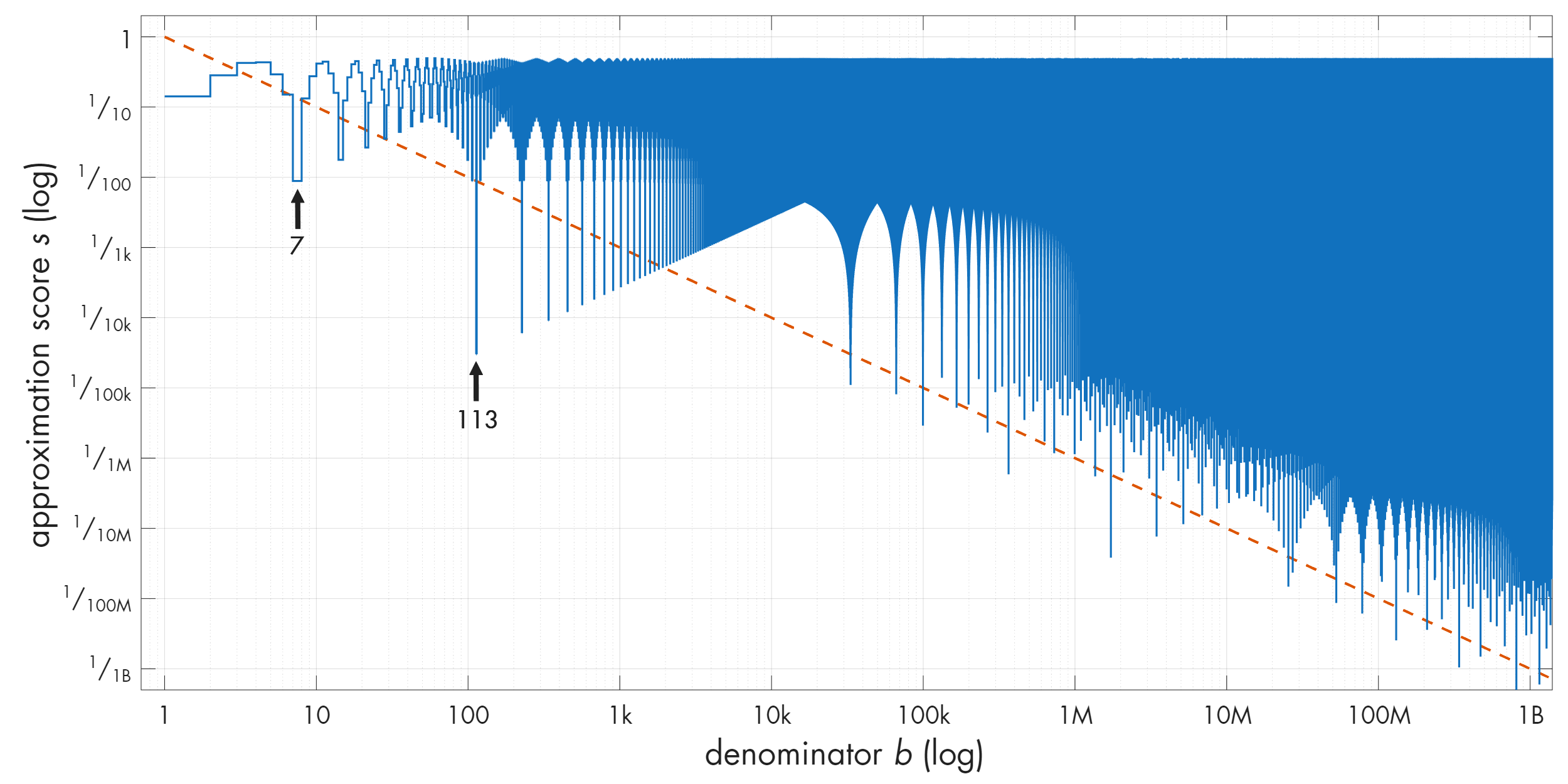
Note that the plot keeps dipping below the 2-good line over and over again. And there are some really nice approximations in there! The first arrow points to 22 / 7 ≈ 3.143 (s ≈ 0.009). The second arrow points to an even better one: 355 / 113 ≈ 3.141593 (s ≈ 0.00003). What’s up with that?
Before we investigate, let’s confirm that π is not special. Surely enough, these patterns crop up for other irrationals too. And it’s not just famous transcendental constants; here’s √42:
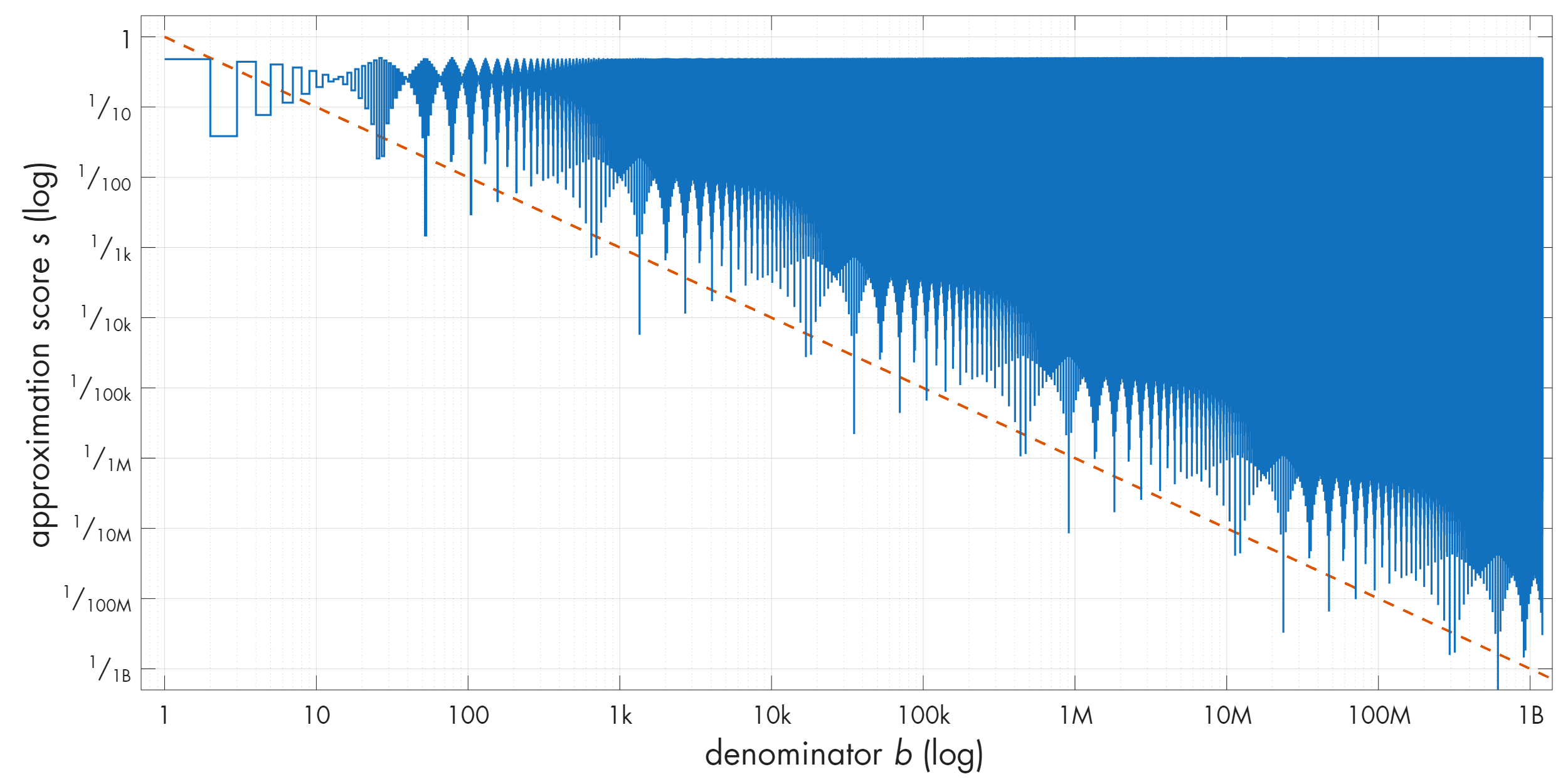
To understand what’s going on, we need to build a lengthier proof, although we’ll still stay within the realm of middle-school math.
First, we make a simple observation: given some number r, we can always split that number into an integer part v and a fractional remainder x that satisfies 0 ≤ x < 1. In other words, we’re rewriting r as v + x such that x falls in the interval [0, 1).
We can also deconstruct any multiple of r the same way. In particular, we can calculate k · r for every integer k between 0 and some arbitrary upper bound K > 0; for each of the resulting values, we can then split the result to obtain a sequence of integer parts (v0 to vK) and fractional parts (x0 to xK). A simple illustration of this idea for π is:
These integer and fractional sequences both have K + 1 elements because we started counting at zero.
As asserted before, each fractional part falls somewhere in the interval [0, 1). Next, we divide this interval into K sub-intervals (“buckets”) of equal size:
We have K buckets and K + 1 fractional x values, x0 to xK, that are distributed across these buckets. No matter how we slice and dice it, at least two x values will necessarily end up in the same bucket. This is the pigeonhole principle.
Again, the reasoning implies that there’s at least one pair of indices, g < h, such that xg and xh both ended up in the same bucket. We don’t know anything about these indices or the fractional values they reference, except that by the virtue of being in the same bucket, the values must be less than the width of the bucket (1 / K) apart:
The inevitability of a pair of elements with spacing of less than 1 / K is the crux of the proof. The rest is just a bit of manipulation to relate these elements to a rational approximation of the starting number r.
We show this in a couple of steps. First, recall that for any index k, xk is a deconstruction of a specific multiple of the aforementioned starting number: k · r = vk + xk. This means we can rewrite any xk as the difference between the k-th multiple of r and the associated integer part vk. After making these substitutions for indices h and g, we get:
Next, we group the r-coupled and r-free terms, obtaining what appears to be two independent integers: (vh - vg) and (h - g). We label these a and b:
We don’t need to dwell on the possible values of a; it’s enough that the number can exist. We’re also not concerned about the exact value of b, although we ought to note that it’s always positive (because we specified g < h) and that it’s necessarily less than or equal to K (because it represents the difference of indices in a list with K + 1 elements).
We’ll lean on these properties soon, but for now, let’s bake a and b into the earlier inequality to obtain:
Remember the flag for later and divide both sides by b to get:
Huh — the left-hand portion of the expression is the same as the earlier formula for calculating the error (ε) for an approximation of r with a rational fraction a / b. In other words, the inequality seems to be saying that, as a consequence of the pigeonhole principle, we can pick any r and any K > 0, and there’s always some (unknown) integer a / b that approximates r with an error of less than 1 / (K · b).
We haven’t picked any specific K, but we know that b is always less or equal than K; again, this is because we defined b as a substitution for h - g, the delta between two indices in a sequence of K + 1 elements. Therefore, the expression in the denominator — K · b — involves multiplying b by a value that’s equal or greater than b. In effect, we have proof that for any real r, some a / b satisfies ε < 1/b².
This proof is known as Dirichlet’s approximation theorem. At first blush, it only guarantees a single 2-good approximation for every real. Worse yet, the solution guaranteed by the proof might not comply with the rules of our game, because nothing stops it from producing exact approximations (ε = 0). So, what did we achieve?
Well, that’s where we come back to an intermediate equation marked with ⚑:
In the earlier course of the proof, we divided the left-hand side of this inequality by b to arrive at the formula identical to ε. Equivalently, we can say that the current form is equal to ε · b. We already have a name for this parameter: this is the denominator-normalized approximation score s, as introduced early in the article.
We can also assert that for any irrational r, the left-hand side of that inequality must be greater than zero. To prove this property, it’s sufficient to show that we’d end up with a contradiction if multiplying r by some positive integer (b) produced some sort of a rational number — that is, if it netted an ad hoc fraction h / j, where h and j are also integers. If r · b = h / j, we can represent r itself as a fraction, making it rational:
In other words, if r is irrational, the same must hold for r · b. Since r · b is an irrational number and not an integer, subtracting an integer from it will always leave a fractional part. Therefore, s = | r · b - a | must be > 0.
To take the next step — and we’re close to the finish line! — note that Dirichlet’s proof doesn’t put any constraint on the upper value on the number of buckets (K). If we choose some specific K1, the earlier proof establishes the existence of a single 2-good pair, which we can label a1 and b1. If we choose another value K2, the proof establishes the existence of a potentially different pair we’ll call a2 and b2. That said, who knows if the pairs actually differ? Maybe there’s just a single solution that repeats for every K?…
Let’s assume that’s the case; if the resulting approximations are identical, the same goes for the normalized approximation error: s = s1 = s2. To restate this more explicitly, we’re entertaining the possibility that this single value satisfies the flagged inequality in proofs carried out for both values of K: s < 1 / K1 and s < 1 / K2.
At the same time, we have noted that in the irrational case, s must be positive. Real numbers can be arbitrarily small, but they can’t be infinitely small, so for any positive s that obeys the first inequality, we can make the 1 / K2 fraction in the second proof smaller than s simply by choosing a sufficiently large K2. This breaks the second inequality and leads to a contradiction. We must conclude that, for some K2 > K1, we necessarily get a new, better approximation (s2 < s1).
Further, if we keep incrementing K, this new a2 / b2 approximation will eventually succumb to the same fate. We can evidently get as many 2-good pairs as we want. The proof doesn’t guarantee that it’s going to happen on any specific cadence, but it says that the outcome is inevitable.
As a postscript, we ought to ask if the same reasoning applies to rationals; if it does, that would contradict our earlier argument that rational numbers can only have a handful of 2-good solutions. To show that there is no contradiction, note that in the rational case, s can conceivably reach zero (i.e., there is some a / b value that is an exact approximation). The rules of our game reject these approximations, but as discussed earlier, the same constraint is not baked into Dirichlet’s proof — and right now, we’re just trying to understand what the proof implies or doesn’t imply.
Next, because we’re talking about a rational r, let’s rewrite it as p / q in the left-hand portion of the earlier inequality:
The numerator of the fraction on the right is an integer (because so are a, b, p, and q). The denominator is also an integer that stays constant for a given r. It follows that when approximating rationals, there is a fixed, minimum decrement for s: 1/q. We might start from a non-zero s1, but if we keep ramping up K, the system must reach the degenerate sn = 0 case after producing a finite number of inexact approximations. From that point on, s < 1 / K is satisfied for any K and the proof no longer necessitates the generation of additional 2-good pairs.
As before, we can’t cheat by increasing p in tandem with q (e.g., r = 1/2 to r = 4/8). This trick increments the nominator and the denominator by the same factor, still producing the same effective step; the solution is predicated on the lowest-terms representation of r = p / q.
In the end, you get an infinite supply of surprisingly accurate solutions for irrational numbers, but a limited (often very limited) number of decent results for rationals.
But… why?
Right. The proofs are interesting but don’t offer an intuitive explanation of why these patterns emerge. This is where we go back to my opening remark: it’s easier to grasp the outcome if you look at how rational numbers and reals are “made”.
From the construction of rationals, we know that the spacing between them is arbitrarily close, but at any “magnification level” — for any chosen denominator b — the values divide the continuum into uniform intervals. Uniform spacing also implies maximal spacing: even though there is no upper or lower bound to the values of a / b, they are as far apart as they can be. Any new value inserted onto the number line will necessarily sit “closer” to an existing rational.
The gaps between rational numbers is where we find irrationals. This comes with a lot of weird baggage explored in the previous article, but it also means that for any given irrational r, we have an inexhaustible supply of unexpectedly accurate rational approximations in the vicinity.
Although the puzzle we started with might seem silly, the study of these structures — known as Diophantine approximations — is taken seriously and gets complicated fast. For example, it’s possible to construct so-called Liouville numbers that have an infinite irrationality exponent (endless n-good approximations for any n), but it’s a lot harder to prove that any commonly-encountered number has an irrationality exponent greater than two. In the same vein, algebraic irrationals (e.g., √2) all have an irrationality measure of two, but the proof of this is fiendishly difficult and netted its discoverer the Fields Medal back in 1958.
You might also enjoy my other articles about math, including:



I write well-researched, original articles about geek culture, electronic circuit design, algorithms, and more. If you like the content, please subscribe.
Three postscripts:
1) The idea for the game comes from a book by Robin Pemantle and Julian Joseph Gould: https://www.amazon.com/dp/1032870346 . That said, the book is less accessible and uses differently-structured proofs.
2) To recreate the plots in the article, you can calculate scores this way:
tgt_b = target_float * b;
high_alpha = floor(tgt_b) + 1 - tgt_b;
low_alpha = tgt_b - ceil(tgt_b) - 1;
...where target_float is the representation of the number you're approximating and low_alpha / high_alpha are the low-side and high-side errors you can plot. My implementation using arbitrary precision floats can be found here: https://lcamtuf.coredump.cx/blog/gmp_approximator.c
3) Rational numbers have a limited number of 2-good approximations and these approximations tend to be crummy. But if you want to construct a rational with some number of nice approximations... well, just take some of the initial digits of π!
I've always found a good way to get a geometric intuition about this fact is to think of the denominator and numerator of the rational approximation as two orthogonal axes with integer values. A lattice of points going from 1-... on each axis forming a 2D lattice of dots.
An irrational number is represented as a line that you draw from the origin through the lattice that *never* touches any of the infinite lattice points. It's slope is the numerical value.
But it is easy to see that the line gets awfully close to some lattice points. Arbitrarily close.
It is fun to actually try to do this on graph paper. It's really hard to draw a line and *not* hit any dots, even for a small lattice like 20x20.
Wikipedia has a pretty good image:
https://en.wikipedia.org/wiki/Integer_lattice#/media/File%3ADiophantine_approximation_graph.svg